If you've ever spent any amount of time experimenting with local AI models, you've almost certainly experienced the same cycle I have.
LLMFit takes the guesswork out of running local AI modelsIt's a hardware-aware recommendation engine for local LLMsLLMFit is essentially a recommendation engine for local AI models that makes your job a lot easier if you're getting into self-hosted AI.
How to install LLMFit on your Windows deviceJust three commands to get startedTo install LLMFit on your device, the first thing you need on a Windows machine is Scoop.
Subscribe to the newsletter for local AI model guidance Discover curated model picks by subscribing to the newsletter: hardware-aware recommendations, setup tips, and LLMFit-aligned suggestions to help you choose and run local AI models without guesswork.
The problem, however, came when I took a closer look at the laundry list of AI models inside the tool.
If you've ever spent any amount of time experimenting with local AI models, you've almost certainly experienced the same cycle I have. You find an exciting new model, fire up Ollama or Hugging Face, wait for the download to finish, only to find out that the new model either crawls along at two tokens per second, or just refuses to fit into memory. Between my laptop, gaming PC, my partner's PC, and the occasional test bench, if I had a dollar for every time that happened, I'd have at least enough to pay for half a month's worth of Claude Pro.
This is where LLMFit comes in. Instead of leaving you to guess which models your hardware can handle as you scratch your head looking at different quantizations and parameter counts, LLMFit analyzes your system and recommends the AI models that should run well. Plenty of cloud AI users are slowly moving over to self-hosting their local AI models, and if you're one of them, LLMFit should be the first thing you use to get a proper lay of the land.
LLMFit takes the guesswork out of running local AI models
It's a hardware-aware recommendation engine for local LLMs
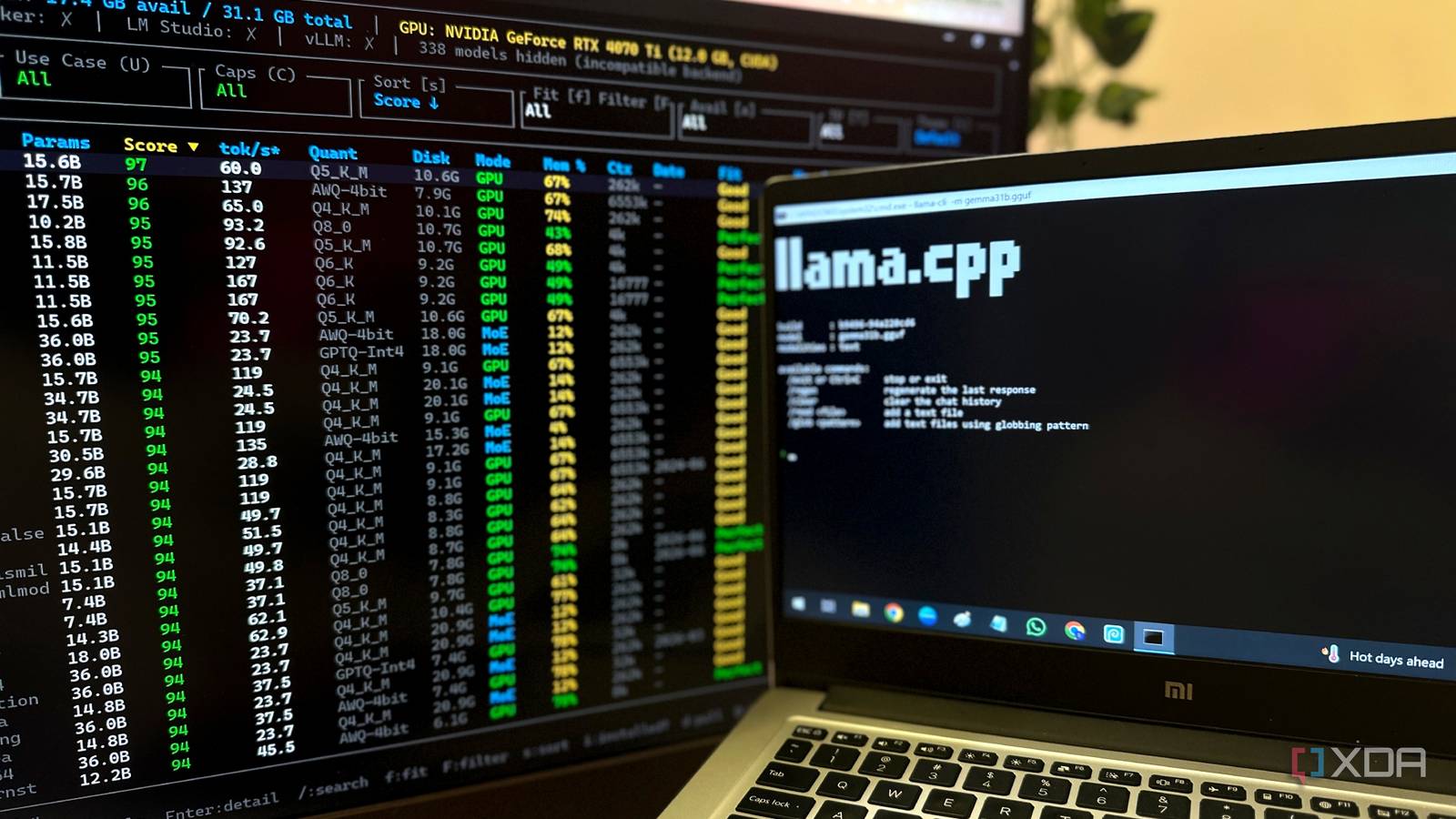
LLMFit is essentially a recommendation engine for local AI models that makes your job a lot easier if you're getting into self-hosted AI. Before you commit to a massive download for a 10-, 15-, or 20-GB model, it figures out whether your hardware can realistically handle such a model first. Once you install and run it, LLMFit will evaluate your CPU, GPU, and available RAM and VRAM before ranking over 250 models according to how well they'll perform on your machine.
The star of the show here is the "Fit" score, which rolls speed, context length, and quality all into one to score a model out of a hundred points. So, instead of forcing you to decipher pages of benchmarks, it will give you a practical shortlist of models that are actually worth your time. Sure, if you're sitting on a workstation with enough VRAM to make enterprise AI labs blush, you'll have no shortage of options anyway, but for the rest of us working within the confines of consumer hardware, this is exactly the kind of problem LLMFit exists to solve.
It doesn't stop at recommendations, either. LLMFit integrates directly with Ollama and llama.cpp, so once you've found a model that fits the bill, you can launch it without bouncing between different applications. Alongside each recommendation, there's something particularly helpful for newcomers, which is a workload label — the tool tells you whether a model you're eyeing is best suited for coding, chat, image generation, or MoE (mixture of experts) tasks. That directly translates into less time Googling model names, and more time actually using them.
How to install LLMFit on your Windows device
Just three commands to get started
To install LLMFit on your device, the first thing you need on a Windows machine is Scoop. Scoop is a well-trusted command-line installer for Windows. To install Scoop, simply paste the following line of code into an elevated PowerShell window:
Set-ExecutionPolicy -ExecutionPolicy RemoteSigned -Scope CurrentUser
Here, odds are you'll either see no response and the command will work properly, or PowerShell will ask you if you want to change the execution policy. Press Y and hit Enter. Copy the next line into the same window:
Invoke-RestMethod -Uri https://get.scoop.sh | Invoke-Expression
This will install Scoop on your Windows device. The next thing you need to do is to open a Command Prompt window and simply type in the following:
scoop install llmfit
With that, LLMFit is installed on your device. Just type in llmfit into a CMD or PowerShell window, and it will immediately pop up with all its data on local AI models that you can install and run on your device.
I tested LLMFit on a six-year-old laptop
It told me exactly which model worked best
Once I installed LLMFit on my six-year-old laptop, it quickly detected the hardware and listed models that it thought would work best on it. This is an old Mi laptop bought in 2019, with all of 8GB RAM, and an Intel i5-10210U CPU running at 1.60 GHz. In the graphics department, it's got nothing to boast other than Intel UHD integrated graphics. Even on this old piece of hardware, LLMFit only took a handful of seconds to be up and running after it detected my device's capabilities.
LLMFit is a keyboard-only tool. It operates operates like an old motherboard BIOS interface.
LLMFit gave Microsoft's Phi-mini-MoE-instruct model an impressive 90.4 out of 100 on the composite score, listing it at the very top of the list for what would run best. The tool estimated that I would get around 40-42 tokens per second running this 7.6B-parameter model in llama.cpp, so I immediately downloaded the exact quantization LLMFit suggested (Q4_K_M).
Subscribe to the newsletter for local AI model guidance Discover curated model picks by subscribing to the newsletter: hardware-aware recommendations, setup tips, and LLMFit-aligned suggestions to help you choose and run local AI models without guesswork. Get Updates By subscribing, you agree to receive newsletter and marketing emails, and accept our Terms of Use and Privacy Policy . You can unsubscribe anytime.
Thankfully, there's the option to download a model directly from the tool itself, and with the press of the "d" key, I immediately downloaded the AI model from Hugging Face. When I ran it, I didn't quite get the tokens and speed LLMFit promised, but it was still in the 20-25 token-per-second category.
The problem, however, came when I took a closer look at the laundry list of AI models inside the tool. A lot of those models listed are old and obsolete already, which immediately signaled to me that the app requires way more models updated into it and with much more frequency. As a stepping stone, however, I don't see the downside to installing LLMFit and using it with your hardware to get a lay of the land before downloading big AI models to use locally.
LLMFit A terminal tool that right-sizes LLM models to your system's RAM, CPU, and GPU. Detects your hardware, scores each model across quality, speed, fit, and context dimensions, and tells you which ones will actually run well on your machine.
Should everyone using local AI models use LLMFit?
Until you learn how parameter counts and quantizations affect your hardware, LLMFit removes most of the trial and error.
For me, LLMFit is best viewed as a stepping stone rather than a tool you'll rely on forever. It only takes a few weeks of experimenting with local AI before you develop a good feel for your own hardware. Once you learn how parameter counts, quantizations, and memory requirements affect performance, you'll also start making educated guesses yourself. Until you reach that point, though, having a tool that removes most of the trial and error is genuinely valuable. It gives you the confidence to download models knowing there's a good chance they'll perform the way you expect.
That became especially clear when I helped a friend dip their toes into local AI on an Acer Nitro 5 with an RTX 3050 Laptop GPU. We didn't have to download endless models and go through all of them to see which worked best. LLMFit just immediately surfaced models that made sense for the hardware and paired perfectly with Ollama, llama.cpp, and other self-hosted front ends. More than anything, though, it smooths out those first few self-hosting adventures, replacing frustration with momentum and helping newcomers build a solid foundation without wasting hours on models that were never going to run well in the first place.