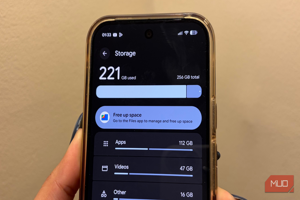
SPEC CPU 2017 NAB test showed ~12% speedup on modern AMD and Intel CPUs.
Now, someone has stepped forward and claimed that a single line change in the GCC compiler added a 12% performance boost for modern AMD and Intel chips in a SPEC CPU 2017 benchmark.
All Cui did was add 3 to the scale, and now the compiler is a lot warier about generating standard branching code.
Cui noted a 12% increase in performance for both Intel and AMD chips, as they spent less time backtracking and more time churning through code.
It'll be a while until we see this change, as it's merged for GCC 17, releasing next year.
Summary Adding 3 to GCC's branch-misprediction scale makes it warier of branch mispredictions.
SPEC CPU 2017 NAB test showed ~12% speedup on modern AMD and Intel CPUs.
The change is due to arrive in GCC 17, coming in 2027.
It has been a weird month for really small code adjustments that score noticeable performance wins. It was only a few days ago that we learned that someone modified three lines of code in the Linux kernel and achieved a 5% storage speed boost because of it. Now, someone has stepped forward and claimed that a single line change in the GCC compiler added a 12% performance boost for modern AMD and Intel chips in a SPEC CPU 2017 benchmark.
Adding 3 to a variable scored big wins for new AMD and Intel processors
In all fairness, it was a very impactful addition of 3
As spotted by Phoronix, Intel software engineer Lili Cui has found a way to squeeze out more performance with minimal changes to the GCC compiler. The exact process Cui used to get this additional performance is a little complex, so let's break it down.
When a CPU runs code, it tries to "cheat" to boost its performance. When a CPU encounters a decision in the code (such as an if/else statement), it 'should' wait for the calculations to tell it which road to take. However, with a process called "speculative execution," the CPU predicts the program's next instruction and begins processing the subsequent code in advance.
It's sort of like sending a text to your friend asking if they want a burger or a pizza, then assuming they'll want a burger and getting a patty on the grill. If you're right, you can get the burger cooked faster and impress your friend with your speed. If you're wrong, you have to stop, clean everything up, and cook a pizza instead. Similarly, an incorrect guess from the CPU means it has to go back to the decision and take the other path.
This is called a "branch misprediction," and Cui noticed that performing them on modern CPUs costs more performance than people first assumed:
Modern CPUs have deeper pipelines, making branch mispredictions more expensive. Increasing this cost encourages if-conversion, avoiding pipeline stalls from mispredicted branches.
To fix this, Cui modified the line of code that defined the branch misprediction scale, which GCC's internal code-generation math uses to gauge if it's worth the risk to gamble on a branch. All Cui did was add 3 to the scale, and now the compiler is a lot warier about generating standard branching code. This makes it more likely to optimize the code another way, such as with a branchless sequence.
Deals Save on CPUs, desktops and workstations — deals now Discover discounts across computers and work-setup gear — find deals on CPUs, desktops, laptops, motherboards, RAM, cooling, monitors, docks, and peripherals. Stock up on upgrades and accessories to squeeze more performance from your setup while saving money.
Once done, Cui put their processors through a SPEC CPU 2017 benchmark called the 544.nab_r Nucleic Acid Builder (NAB), which calculates the physics and chemistry of molecules. Cui noted a 12% increase in performance for both Intel and AMD chips, as they spent less time backtracking and more time churning through code.
It'll be a while until we see this change, as it's merged for GCC 17, releasing next year. However, it's a cool story about how one little tweak can make a huge difference.